
Demystifying the Creation of Data for RAG: Unleashing the Power of Knowledge
The incredible world of Retrieval-Augmented Generation (RAG) begins with one crucial element – data. But how is this data created, curated, and harnessed to fuel the RAG engine? Buckle up as we embark on an enlightening journey into the data creation process behind this transformative technology!
1. Data Gathering and Collection
The first step in creating data for RAG involves gathering diverse and extensive datasets. This process includes scraping information from the internet, collecting documents, articles, books, and more. The goal is to amass a wealth of knowledge covering various domains and topics.
2. Data Preprocessing and Cleaning
Raw data can be messy. Preprocessing steps, such as removing duplicate entries, handling missing values, and standardizing formats, are essential to ensure the data is clean and ready for use. This meticulous preparation sets the stage for accurate retrieval and generation.
3. Building Knowledge Graphs
Knowledge graphs are the backbone of RAG. They organize information into a structured format, linking concepts, entities, and their relationships. Creating these graphs requires semantic analysis and entity recognition techniques, making the data richer and more navigable.
4. Annotating and Tagging
To enable effective retrieval and generation, data is annotated and tagged. This involves identifying key entities, relationships, and context within the text. These annotations act as signposts for RAG models, guiding them to relevant information.
5. Training Retrieval Models
RAG relies on retrieval models to fetch pertinent information. These models are trained on curated data, learning to identify relevant documents, passages, or knowledge graph nodes in response to specific queries or prompts. This step enhances the accuracy of information retrieval.
6. Fine-Tuning Generation Models
The generation aspect of RAG is powered by language models like GPT. Fine-tuning these models involves exposing them to the curated data and training them to generate coherent, contextually relevant text that integrates retrieved knowledge seamlessly.
7. Continuous Updates
The world of information is ever evolving. To keep RAG models up to date, a continuous process of data refreshment is crucial. New data is periodically incorporated, ensuring that RAG remains a valuable resource in the face of changing knowledge landscapes.
The creation of data for RAG is a meticulously crafted process, merging the art of data curation with the science of AI. It's about building a knowledge repository that empowers RAG models to deliver insightful, context-aware responses and content generation. Stay tuned for more insights into how RAG is reshaping industries worldwide!
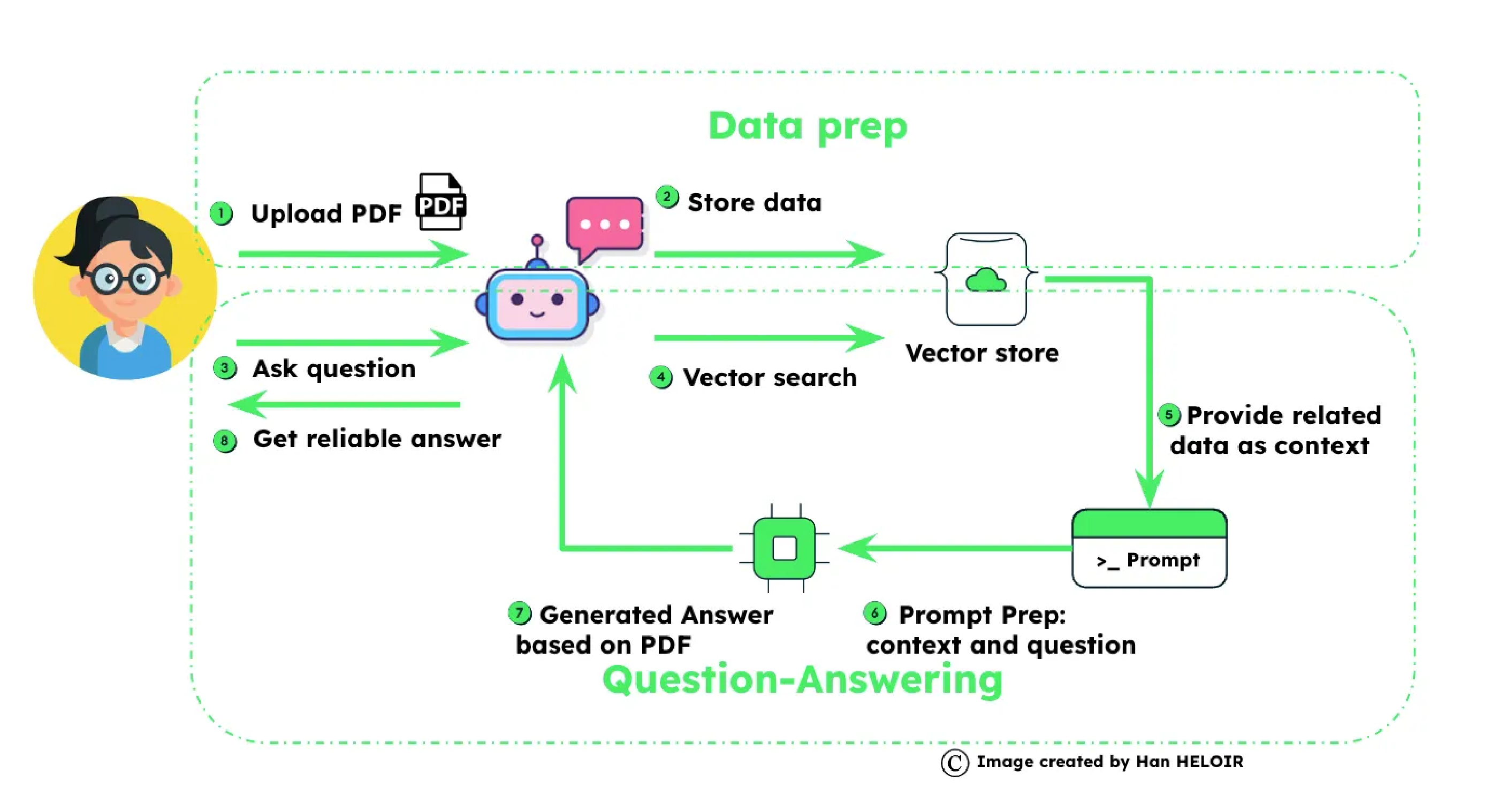
Here is an excellent example of using RAG data to create a chatbot. "From Zero to Hero: Building a Generative AI Chatbot with MongoDB and Langchain" from Han HELOIR, Ph.D.



